
Neuigkeiten
Paper für den Workshop eLVM@CVPR 2024 akzeptiert
Ein Paper mit dem Titel ?Adapting the Segment Anything Model During Usage in Novel Situations“ von Robin Sch?n, Julian Lorenz, Katja Ludwig und Rainer Lienhart wurde auf dem Workshop für ?Efficient Large Vision Models (eLVM)“ akzeptiert. Dieser Workshop findet im Rahmen der CVPR 2024 in Seattle statt. Das Paper stellt eine Methode vor, um das Segment Anything Model (SAM) ohne Zuhilfenahme von zus?tzlichen Trainingsdaten zur Testzeit anzupassen. Anstelle dessen werden Information, welche w?hrend der Verwendung des Systems anfallen, zur Generierung von Pseudolabels verwendet.
Paper für SG2RL@CVPR 2024 akzeptiert
Das Paper "A Review and Efficient Implementation of Scene Graph Generation Metrics" von Julian Lorenz, Robin Sch?n, Katja Ludwig und Rainer Lienhart wurde beim Workshop on Scene Graphs and Graph Representation Learning auf der CVPR 2024 akzeptiert.
?
Die Autoren schaffen einen ?berblick über existierende Scene Graph Generation Metriken und pr?sentieren pr?zise Definitionen, die bisher noch nicht gegeben waren. Au?erdem stellen die Autoren ein Pythonpaket vor, dass eine effiziente und leicht zu verwendende Implementierung der eingeführten Metriken bietet. Um Scene Graph Generation Methoden in Zukunft besser vergleichen zu k?nnen wird ein Benchmarking-Service eingerichtet, über den neue Methoden leicht verglichen werden k?nnen.
?
Weitere Informationen sind unter https://lorjul.github.io/sgbench/ zu finden.
?
Offene Stellen für Doktoranden
Wir sind immer auf der Suche nach exzellenten Forschern, die für Forschung und eine Promotion brennen. Forschungsschwerpunkt unseres?Lehrstuhls ist das maschinelle Lernen und Wahrnehmen (Sehen/H?ren/andere Sensormodalit?ten). Ein aktuelles?Forschungsthema ist z.B. ?Lebenslanges und kontinuierliches Lernen in Einzel- und Multiagentensystemen mit sporadischem menschlichem Feedback“.
Bewerbe Dich (w/m/d) mit Lebenslauf und bisherigen Studiumsnoten.

Paper auf der International Conference on 3D Vision (3DV) 2024 akzeptiert
Das Paper mit dem Titel "Towards Learning Monocular 3D Object Localization Using the Physical Laws of Motion" von Daniel Kienzle, Julian Lorenz, Katja Ludwig und Rainer Lienhart wurde auf der Internation Conference on 3D Vision (3DV) 2024 akzeptiert. Das Paper beschreibt eine neue Methode, um Objekten in 3D zu lokalisieren, ohne dass 3D-Grundwahrheiten ben?tigt werden. Stattdessen wird das Wissen über physikalische Gesetze genutzt, um diese Aufgabe zu lernen.
?
Weitere Informationen zu diesem Paper sind unter
Paper für SG2RL @ ICCV 2023 akzeptiert
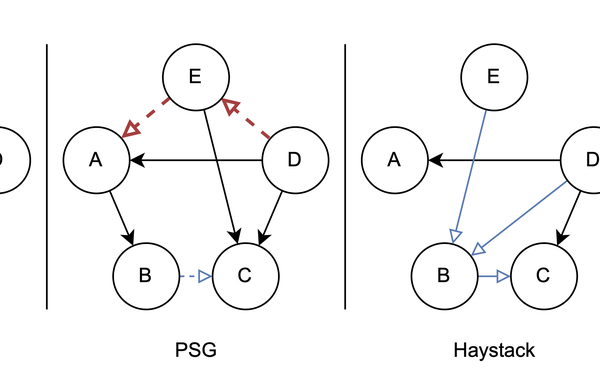
Das Paper ?Haystack: A Panoptic Scene Graph Dataset to Evaluate Rare Predicate Classes” von Julian Lorenz, Florian Barthel, Daniel Kienzle und Rainer Lienhart wurde beim First ICCV Workshop on Scene Graphs and Graph Representation Learning (SG2RL) akzeptiert. Die Autoren pr?sentieren Haystack, einen neuartigen Datensatz für Scene Graph Generation, der entwickelt wurde, um die Schwachstellen der Evaluation mit aktuellen Scene Graph Datens?tzen zu verhindern. Insbesondere zeichnet sich Haystack dadurch aus, dass er seltene Pr?dikatklassen enth?lt und auch negative Annotationen beinhaltet. Erst durch diese Eigenschaften k?nnen seltene Beziehungen zuverl?ssig evaluiert werden. Mithilfe der besonderen Struktur des Datensatzes sind die Autoren in der Lage, drei neue Metriken zu definieren, die verwendet werden k?nnen, um aussagekr?ftigere Aussagen über die Modellausgaben zu seltenen Pr?dikaten zu machen.
?
Weitere Informationen sind unter https://lorjul.github.io/haystack/ zu finden.
Paper auf dem L3D-IVU @ CVPR 2023 akzeptiert
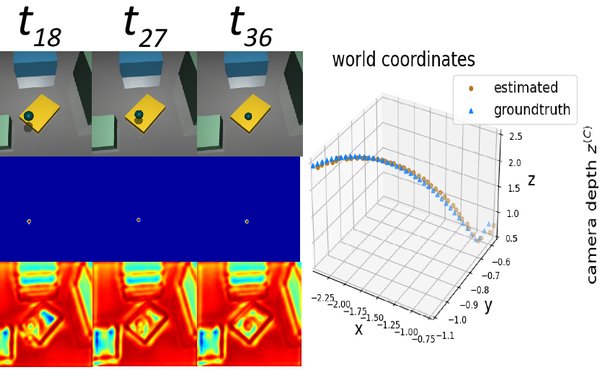
Das Paper mit dem Title "Impact of Pseudo Depth on Open World Object Segmentation with Minimal User Guidance" von Robin Sch?n, Katja Ludwig und Rainer Lienhart wurde auf dem 2nd Workshop on Learning with Limited Labelled Data for Image and Video Understanding at the CVPR 2023 akzeptiert. In diesem Paper untersuchen die Autoren den Effekt von Pseudotiefenkarten auf die Segmentierung von Objekttypen, welche nicht in den Trainingsdaten vorkamen. Die zu segmentierenden Objekte werden mithilfe von Koordinaten auf der Objektoberfl?che identifiziert. Um eine Abh?ngigkeit von Grundwahrheitstiefenkarten zu vermeiden, werden die Tiefenkarten mit Netzen generiert.

Paper für CVSports @ CVPR 2023 akzeptiert

Paper für CV4WS@WACV 2023 akzeptiert
Das Paper mit dem Titel "Detecting Arbitrary Keypoints on Limbs and Skis with Sparse Partly Correct Segmentation Masks" von Katja Ludwig, Daniel Kienzle, Julian Lorenz und Rainer Lienhart wurde auf dem Workshop Computer Vision for Winter Sports auf der?IEEE/CVF Winter Conference on Applications in Computer Vision (WACV) 2023 akzeptiert. Die Autoren beschreiben in diesem Paper, wie beliebige Punkte auf den Gliedma?en und den Ski von Skispringern erkannt werden k?nnen. Für die vorgestellte Methode ist ein Datensatz ausreichend, der nur wenige Segmentierungsmasken enth?lt, und diese müssen auch nur teilweise korrekt sein.

Paper für die BMVC 2022 akzeptiert
Das Paper mit dem Titel "Pseudo-Label Noise Suppression Techniques for Semi-Supervised Semantic Segmentation" von Sebastian Scherer, Robin Sch?n und Rainer Lienhart wurde für die?British Machine Vision Conference (BMVC) 2023?akzeptiert. In diesem Paper beschreiben die Autoren eine Methode die es erm?glich, den Bedarf an gro?en gelabelten Datens?tzen zu verringern, indem nicht gelabelte Daten in das Training einbezogen werden. Als Anwendung verwenden die Autoren die menschlicher Posensch?tzung sowie die semantische Segmentierung, wobei besonderes letzteres interessant ist, da hier die Annotation von Daten ?u?erst zeitaufwendig ist.
Erster Platz beim STOIC-Wettbewerb erzielt: Vorhersagen des Verlaufs von COVID-Erkrankungen mit neuronalen Faltungsnetzen
Daniel Kienzle, Julian Lorenz, Katja Ludwig, Robin Sch?n und Rainer Lienhart vom Lehrstuhl für Maschinelles Lernen und Maschinelles Sehen haben den ersten Platz in der STOIC-Challenge belegt. Das Ziel des Wettbewerbs war es anhand von CT-Scans vorherzusagen, wie sich der Krankheitsverlauf eines Patienten im n?chsten Monat entwickeln würde. Umgesetzt wurde dies mit Hilfe von neuronalen Faltungsnetzen und Transferlernen auf verschiedenen Aufgaben. ?Organisiert wurde der Wettbewerb von Assistance Publique – H?pitaux de Paris, Radboud 新万博体育下载_万博体育app【投注官网】 新万博体育下载_万博体育app【投注官网】ical Center und Amazon Web Services.
Paper für die WACV 2023 akzeptiert
Das Paper mit dem Titel "Uplift and Upsample: Efficient 3D Human Pose Estimation with Uplifting Transformers" von Moritz Einfalt, Katja Ludwig und Rainer Lienhart wurde für die IEEE/CVF Winter Conference on Applications in Computer Vision (WACV) 2023 akzeptiert. In diesem Paper beschreiben die Autoren eine Methode, mit der die Berechnungskomplexit?t von menschlicher Posensch?tzung im 3D Raum mit Transformern erheblich reduziert werde kann. Dennoch k?nnen damit weiterhin zeitlich konsistente und pr?zise 3D Bewegungssequenzen rekonstruiert werden.

Paper für den Workshop on AI-enabled 新万博体育下载_万博体育app【投注官网】ical Image Analysis auf der European Conference on Computer Vision 2022 akzeptiert
Das Paper mit dem Titel "COVID detection and severity prediction with 3D-ConvNeXt and custom pretrainings" von Daniel Kienzle, Julian Lorenz, Robin Sch?n, Katja Ludwig und Rainer Lienhart wurde auf dem Workshop on AI-enabled 新万博体育下载_万博体育app【投注官网】ical Image Analysis auf der ECCV 2022 akzeptiert.
In diesem Paper zeigen die Autoren, wie die ConvNeXt Architektur auf die Klassifizierung von 3D-CT Scans angewendet werden kann. Insbesondere werden verschiedene Methoden untersucht um Transferlernen für die Endanwendung auf medizinischen 3D-Daten durchzuführen. Mit den Erkenntnissen aus diesem Paper wurde der zweite Platz in der 1st COVID19 Severity
Detection Challenge und der dritte Platz in der 2nd COVID19 Detection Challenge erreicht.